
Battle of the LLMs: Picking the right model
With every week new LLMs being launched, how to keep up and judge which one to use?


Nowadays every week new Large Language Models (LLMs) are released. If you're active in the space this can be quite exciting, but then again it can also be quite overwhelming. The landscape is fast-moving and understanding how to choose a LLM is more important than ever.
The choice of picking the right LLM depends on many different factors, for example the task at hand, cost, privacy, the ecosystem and its performance. In this post, we'll try to help you make the right choice by going through
Understanding LLM benchmarks. How does LLM benchmarking work and what are the main benchmarks you should know about?
The battle between open-source and closed-source models. How do the latest models perform on the benchmarks and what is there still to gain?
Cost, data security and ease of use are often overlooked. In some cases other factors like inference cost or data privacy are more important than mere model performance. How can you best take this into account?
TL;DR
If you just want a smaller condensed version of this deep-dive:
LLM benchmarks help by testing how well models perform on tasks like language understanding, math, and coding. But beware that benchmarks that might not match your needs. Don't rely on benchmarks alone; test LLMs with your own data.
Open-source models are often playing catching up to closed-source ones, but they do offer more control and transparency. Nevertheless, remember to also consider costs like inference, fine-tuning and the ecosystem together with data security.
Model selection shouldn't be based solely on benchmark performance. Other crucial factors include costs (API usage, fine-tuning, hosting, and people), data security considerations (especially when using third-party APIs) and ease of integration with existing tools and infrastructure.
1. The need for LLM benchmarks
In today's world it's difficult to keep track of the latest developments in the LLM model space. To help understand the performance of LLM's, benchmarks have been created. But before we dive into which benchmarks are relevant, let's first answer the question of what's an LLM benchmark?
LLM benchmarks are sets of tests that help assess the capabilities of a given LLM model. They answer questions such as: How well can this LLM solve science problems? Can this LLM do well in programming? How well can it act human-like in conversations?
Evaluation of benchmarks
A LLM benchmark can be interpreted as a specialised "exam". Every benchmark includes a set of text inputs or tasks, usually with correct answers provided, and a scoring system to compare the results. In most cases the scoring system rates a model from 0 to 100, where 0 is the worst score and 100 the best. How the score is derived depends on the type of tasks in each benchmark. Here are a few typical scoring mechanisms:
Classification metrics: When the answer can be evaluated as right or wrong classification metrics like accuracy can be used to evaluate performance.
Overlap based metrics: Metrics like ROUGE and BLEU can be used for free-format type of answers. They compare common words and sequences between the model's answer and the reference.
Unit-test based: For coding exercises it's common to evaluate performance of a piece of code on whether it passes pre-made unit-tests.
LLM-based evaluation: In certain cases the scoring is done by another LLM. This can for example be a fine-tuned model that is trained on the questions & answers of a specific benchmark. When it comes to multi-modal capabilities often the LLM-as-a-judge method is used, in which a specialised LLM evaluates the results.
A single benchmark is in most cases not enough to compare model performance. Therefore leaderboards have been created to compare various models on a set of benchmarks. A typical leaderboard looks similar to the one below.
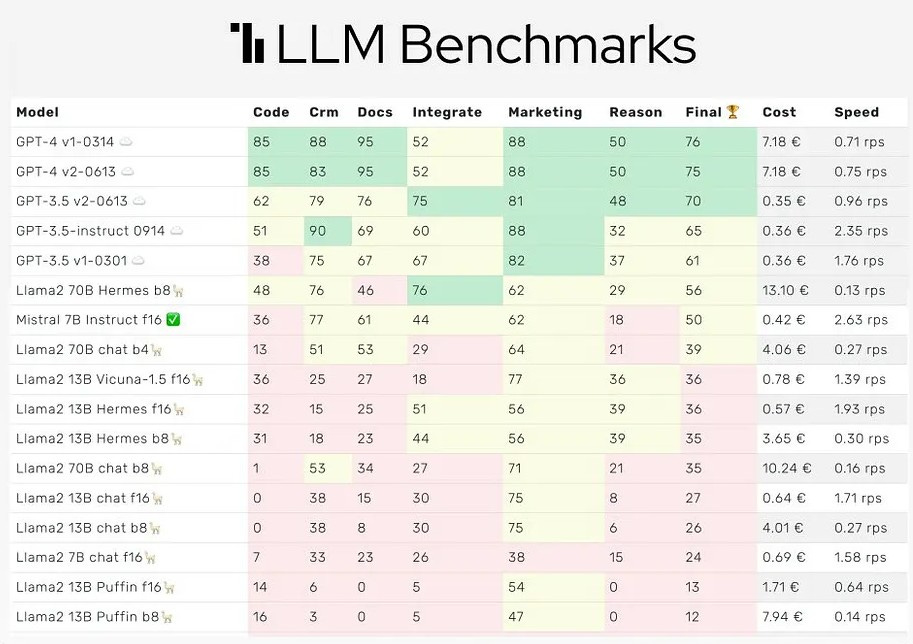
If you're curious to current relevant benchmarks here's an overview of LLM benchmarks hosted by Hugging Face.
Well-known benchmarks
When performance of LLMs is compared it's likely done on a set of well-known benchmarks. These benchmarks are usually quite generic and judge a LLM on a few different criteria. Let's look at a few of the most well-known LLM benchmarks
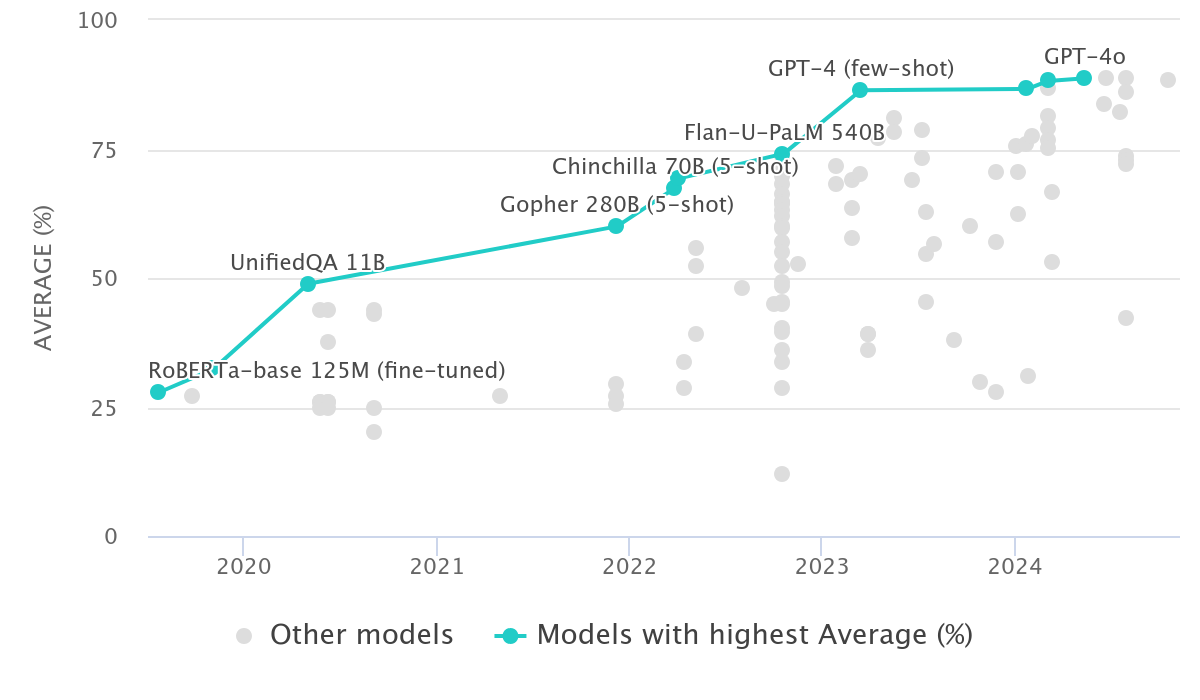
MMLU (Massive Multitask Language Understanding): This multiple-choice test from 2020 (source) was one of the first to test knowledge across a wide range of subjects, from math and history to law and medicine. High scores indicate strong general knowledge and understanding. It was used to determine that a LLM like GPT-3 performs 20% better (~44%) than fully randomised choice answers. In comparison a newer model like OpenAI o1 has twice the score (~91%).
ARC (AI2 Reasoning Challenge): Already developed in 2018 (source), it focuses on advanced question answering, requiring models to use complex reasoning skills to answer science questions. There are both "easy" and "challenge" versions.
GSM8K (Grade School Math 8K): This test (source) is about testing a model's ability to solve grade school math problems. Requires understanding of mathematical concepts and problem-solving skills.
HellaSwag: This test from 2019 (source) was all about testing whether models can finish sentences. It measures the model's ability to choose the most reasonable continuation of a given scenario. It's a test of common-sense reasoning and contextual understanding, mostly trivial for humans.
TruthfulQA: Evaluates the model's tendency to generate truthful answers (source). It measures how well a model can distinguish between truth and falsehood, even in the presence of misleading or adversarial prompts. Crucial for avoiding misinformation.
Big-Bench Hard (BBH): A more recent test (source) that includes a collection of challenging tasks that require a combination of reasoning, knowledge, and problem-solving skills. It's designed to push the limits of LLM capabilities.
HumanEval: One of the most popular test to evaluate coding performance (source). It evaluates the model's ability to generate functional code based on a natural language description.
DROP (Discrete Reasoning Over Paragraphs): Requires reasoning over paragraphs of text to answer questions that involve discrete reasoning steps (source).
Here's how test results of LLM's on MMLU look over time.
Here are two example of questions from the MMLU benchmark.

For evaluating reasoning capabilities, benchmarks like ARC, BBH, GSM8K, and DROP are particularly important. Remember, a model that excels at MMLU might not necessarily be great at complex reasoning tasks.
Coding benchmarks
While a test like HumanEval is made to evaluate code completion performance of a LLM, it usually takes more specialised coding benchmark to get a good understanding of coding performance. Here are some leaderboards that can help you determine which LLM is best to use for coding purposes
Aider Chat Leaderboard: Based on Aider’s polyglot benchmark, it contains exercises from Exercism in many popular programming languages: C++, Go, Java, JavaScript, Python and Rust. The test has 225 exercises which were purposely selected to be among the hardest in each language in the Exercism platform.
BigCodeBench Leaderboard: This test claims to be one of the first that is: easy-to-use, practical and challenging. Even the today's most advanced models struggle on this test. It's a good one to keep an eye at if you're striving to use the best coding model.
Specialised benchmarks
In some cases it makes sense to use a more specialised test. These are examples of more specialised tests
GPQA (A graduate level Google-Proof Q&A benchmark): This benchmark from 2023 (source) contains 448 multiple-choice questions written by domain experts in biology, chemistry and physics. This test is developed in such a way that highly skilled non-domain experts on average on reach 34% accuracy, even with 30 minutes of unrestricted Google access. This test is seen as one of the more difficult ones for LLM's to reach a higher score.
DABStep (Data Agent Benchmark for Multi-step Reasoning): In last week's newsletter I've touched upon this benchmark. It's a benchmark on data analytics tasks that require multi-step reasoning. Tasks are more aligned towards a data professional, e.g. joining tables based on a prompt.
MULTI-Benchmark (Multimodal Understanding Leaderboard with Text and Images): We've mainly looked at text based benchmarks thus far, but if your use case if multi-modal (speech, image, etc) then you will need to use a test like this. This benchmark is a generic multi-modal test with many different types of questions to challenge on a model's multi-modal capabilities.
Bias and limitations
This is where things get tricky. Not all benchmarks are created equal. It's crucial to approach benchmark results with a healthy dose of scepticism. Here are a few key considerations
Benchmark coverage: Does the benchmark truly reflect the tasks you care about? Many benchmarks focus on academic tasks or typical coding exercises that don't necessarily translate to real-world performance.
Data leakage: Was the training data of the LLM included in the benchmark dataset? This can lead to inflated scores that don't reflect true generalisation ability. This is a common and difficult problem to address. Take results of newer models on older benchmarks with a grain of salt.
Benchmark bias: Are the benchmarks biased towards certain types of models or architectures? Some benchmarks may favour models trained on specific types of data or using specific techniques.
Scoring methodology: Is the evaluation methodology sound? Are the prompts clear and unambiguous? Is the evaluation metric appropriate for the task?
If the above concerns you, then it might make sense to evaluate LLM performance yourself. Tools like lmarena.ai make it straightforward to compare responses of models side-by-side. Ultimately, the best way to evaluate an LLM is to test it on your own data and for your own use case. Benchmarks can provide a starting point, but they shouldn't be the sole basis for your decision.
2. Open-source vs. closed-source models
The LLM world has been through rapid changes. Just a few weeks ago, closed-source models from the likes of OpenAI and Anthropic seemed to reign supreme. But the landscape is shifting, and the emergence of models like DeepSeek's R1 has made a huge impact.
DeepSeek has risen in popularity with their recent models showing strong benchmark performance. DeepSeek's V3 and R1 models have demonstrated comparable or even superior performance compared to closed-source models, particularly in coding challenges and reasoning. And with an appealing cost profile, this makes them a significant disruptor. They've shown the open-source community what's possible with a focused approach, pushing others to improve too.
A shifting power dynamic
So, what's the deal with open-source versus closed-source LLMs? For a while, closed-source models like OpenAI's GPT series, Anthropic's Claude and Google's Gemini have dominated the leaderboards. This is due to the massive resources, specific training data, and state-of-the-art architectures that these closed-source models have.
The open-source world is catching up fast though. We're seeing models from the likes of Llama, Falcon, Mistral AI and DeepSeek that rival (and even surpass) the performance of closed-source models on certain benchmarks. It's an exciting shift in the LLM arena.
Think of it like this:
Closed-source (e.g. GPT-4, Claude, Gemini): Often boast state-of-the-art performance, particularly on general benchmarks like MMLU, HellaSwag, and TruthfulQA. Typically, they'll have better zero-shot and few-shot learning skills. However, they're "black boxes". You don't know how they work, and you're relying on their API to surface the results.
Open-source (e.g. Llama 2, Mistral-7B, Falcon, DeepSeek V3/R1): Can be competitive on specific tasks but are capable of matching or even beat closed-source models on well-known benchmarks. In addition, you can fine-tune them on your specific data and deploy them on your own infrastructure. You also have greater transparency. However, they often require more expertise and resources to get the most out of them.
Keep in mind that these are generalisations. The performance of any model depends on the benchmark, the fine-tuning applied, and the specific task you want it to do. Don’t blindly trust the numbers you see.
3. Other criteria: Cost, Security & Ease of Use
A model's performance is a key factor in making a decision to pick a LLM, but there are more things to consider when making the decision. Here are other factors to consider when it comes to picking the right model
Models can have significantly different costs. While one model might take $1 to complete a specific task another model might take 10x or even 20x the cost to produce the same result.
Data security is non-trivial if you don't host the model yourself. If you're dealing with sensitive data you might not want to send that data to a model provider like OpenAI.
Hosting your own model sounds appealing, but can become headache. With smaller models becoming more performant it can become interesting to host models yourself. But be aware that it be quite complexity to do well.
The different kind of costs
Beyond the upfront cost of an API key or the initial investment in hardware, there are several often overlooked costs associated with LLMs:
Inference costs: Using LLMs, especially large ones, can be expensive. Every API call, every generation, costs money. Optimising your prompts and caching results can help reduce these costs.
Fine-tuning costs: Fine-tuning an open-source LLM on your data can significantly improve its performance, but it also requires computational resources and expertise. This can be a significant investment.
Hosting costs: If you choose to deploy an open-source LLM on your own infrastructure, you'll need to factor in the cost of servers, GPUs, and maintenance.
People costs: Don't underestimate the human cost of working with LLMs. You'll need engineers, data scientists, and domain experts to develop, deploy, and maintain these systems.
Before picking an LLM, consider these costs and think about how this aligns with your budget. Use websites like llm-price.com to keep informed on latest pricing.
Ensuring your data is secure
When handling sensitive data, security should always be top-of-mind. When using a closed-source model, you're essentially entrusting your data to a third-party. When it comes to a model provider like DeepSeek it's for example not transparent how they might use the data that you send to them. And while a provider like OpenAI claims to not use the data that you send without explicit consent, you need to carefully review their data privacy policies and security measures to ensure they meet your requirements. This might need specific data processing agreements and even then they might still use your data to train their models in the background.
Open-source models offer more control over data security. You can deploy them on your own infrastructure and implement your own security measures. However, you're also responsible for ensuring the security of the model and the data it processes. You also need to have expertise to do this which can come at a significantly higher cost.
Model providers and ease-of-use
Does your company has specific tooling in place that needs to be compatible with your choice of LLM? Is your company already bought into a specific ecosystem, e.g. Google, Azure, etc? For example, if you already use Google Cloud Platform (GCP) for everything then using Google's Gemini models might be very convenient as they integrate well into Google products. This can significantly help with the ease-of-use.
On the other hand model providers like OpenAI and Anthropic make it easy to use their models in a lot of tools. They are usually the first models that are supported as they are widely used in the community. Therefore, it might be convenient to use their models if you are worried about integrations into various tools.
4. Conclusion
The field of LLM evaluation is complex and keeps on evolving. Here are a few trends to watch:
More realistic benchmarks: There's a shift towards benchmarks that are more aligned with real-world use cases and that better capture the complexities of human language.
Better evaluation metrics: Researchers are developing new metrics that go beyond simple accuracy and that measure qualities like creativity, coherence, and helpfulness.
Explainability and interpretability: There's a growing emphasis on understanding why LLMs make the decisions they do. Techniques like attention visualisation and causal tracing are helping us to peek inside the "black box."
Community-driven evaluation: The open-source community is playing an increasingly important role in LLM evaluation, with projects like the Open LLM Leaderboard by Hugging Face providing valuable insights.
Even when benchmarks paint a certain picture there are more factors at play. For example the choice between open-source and closed-source LLMs. This depends on your specific needs, resources, and priorities. Benchmarking can help you make an informed decision, but it's crucial to approach benchmark results with a critical eye. Don't be afraid to experiment, to test models on your own data and to develop your own evaluation metrics. And don't forget the costs attached, the data security element and ease-of-use. These might be just as important as raw performance.
Thanks for reading another edition of The Data Canal weekly newsletter. If you enjoyed this content, make sure to subscribe to not miss out on any new editions. Next week we will dive into a completely different topic: Careers in Data and how I experienced climbing the Data career ladder and back again. Stay tuned for more.