
Optimising AI with textual feedback: A look at TextGrad and AdalFlow
What if there's a way to optimise for AI model outcomes without needing the change the underlying model? This is a deep-dive into optimising model inputs against any measurable metric.

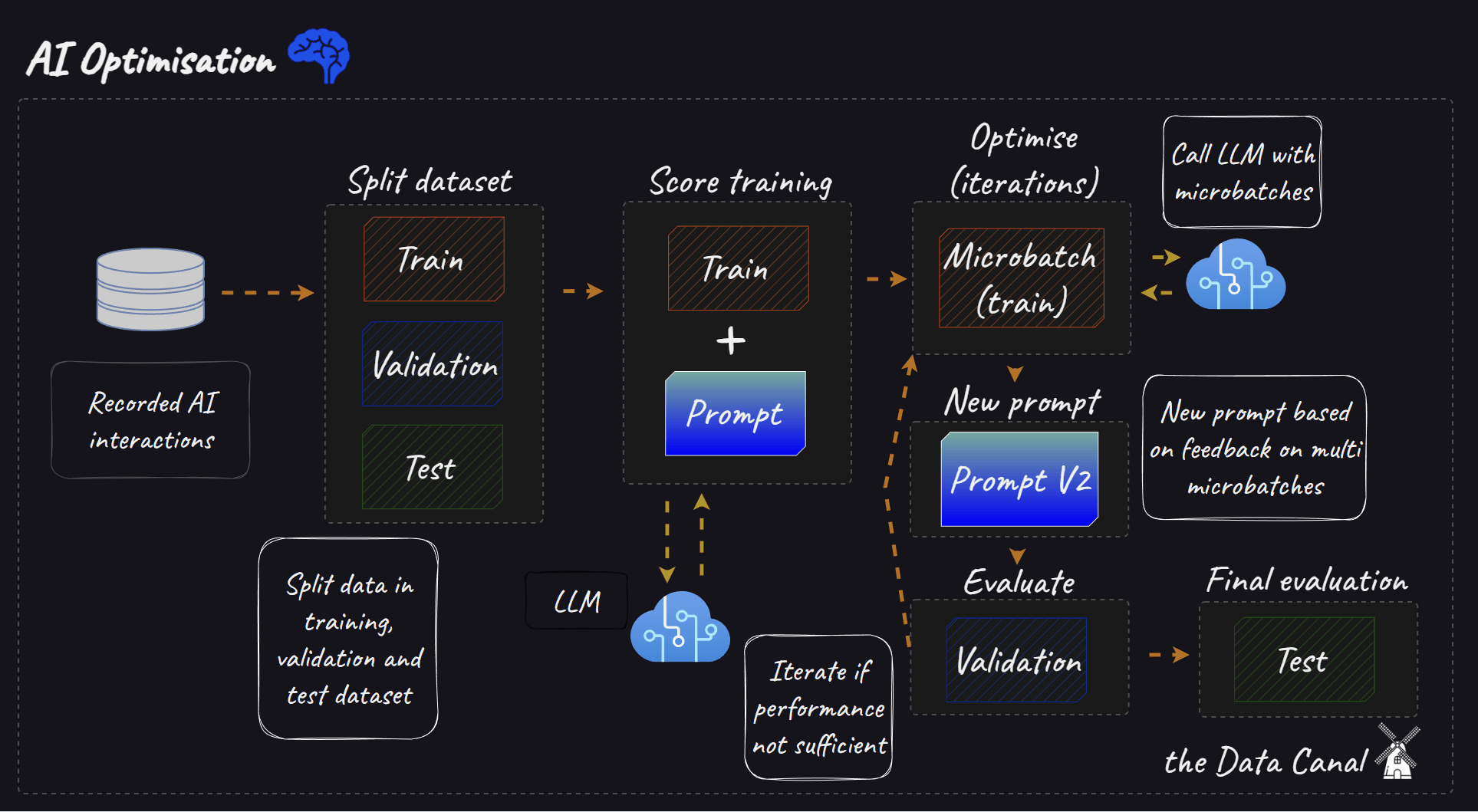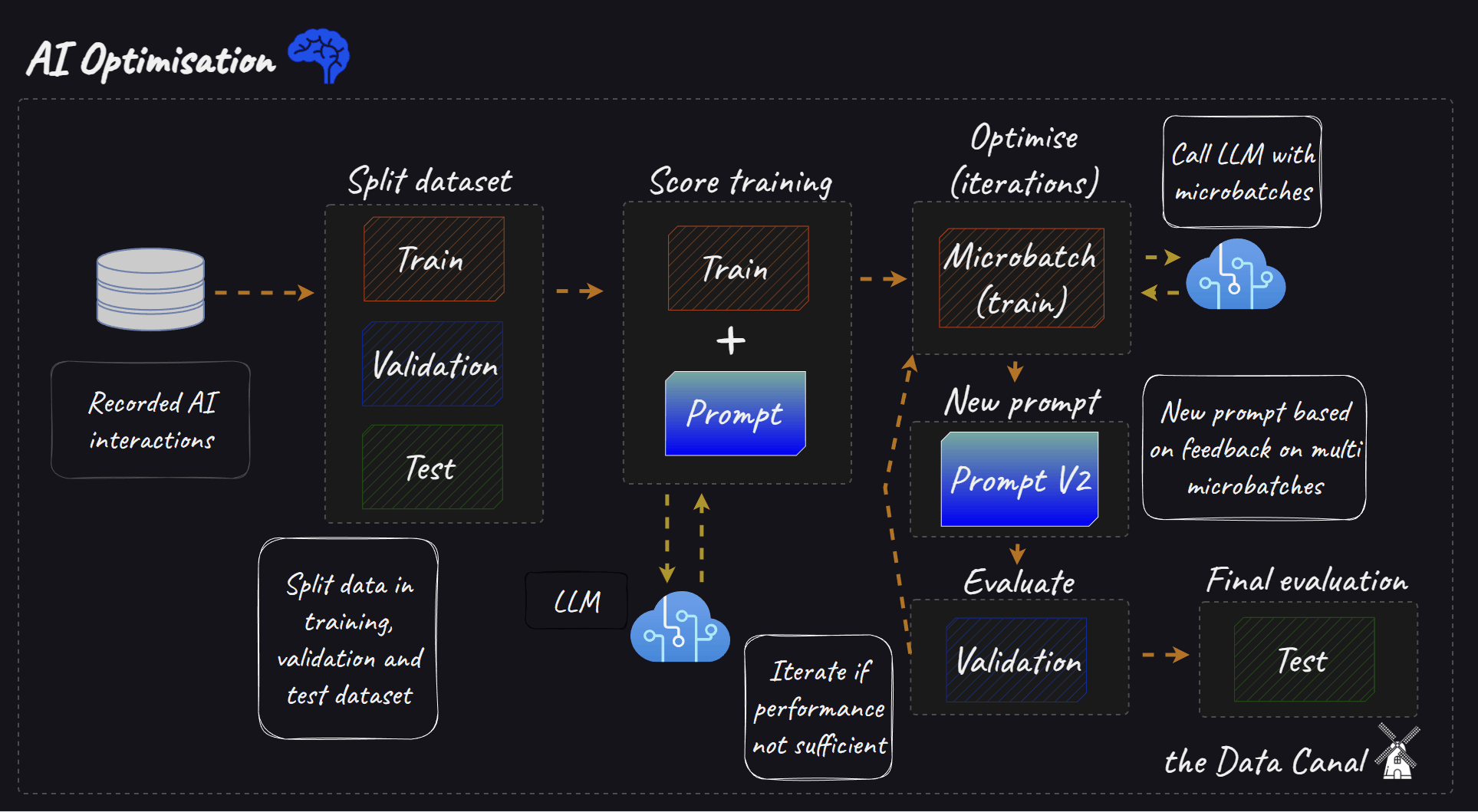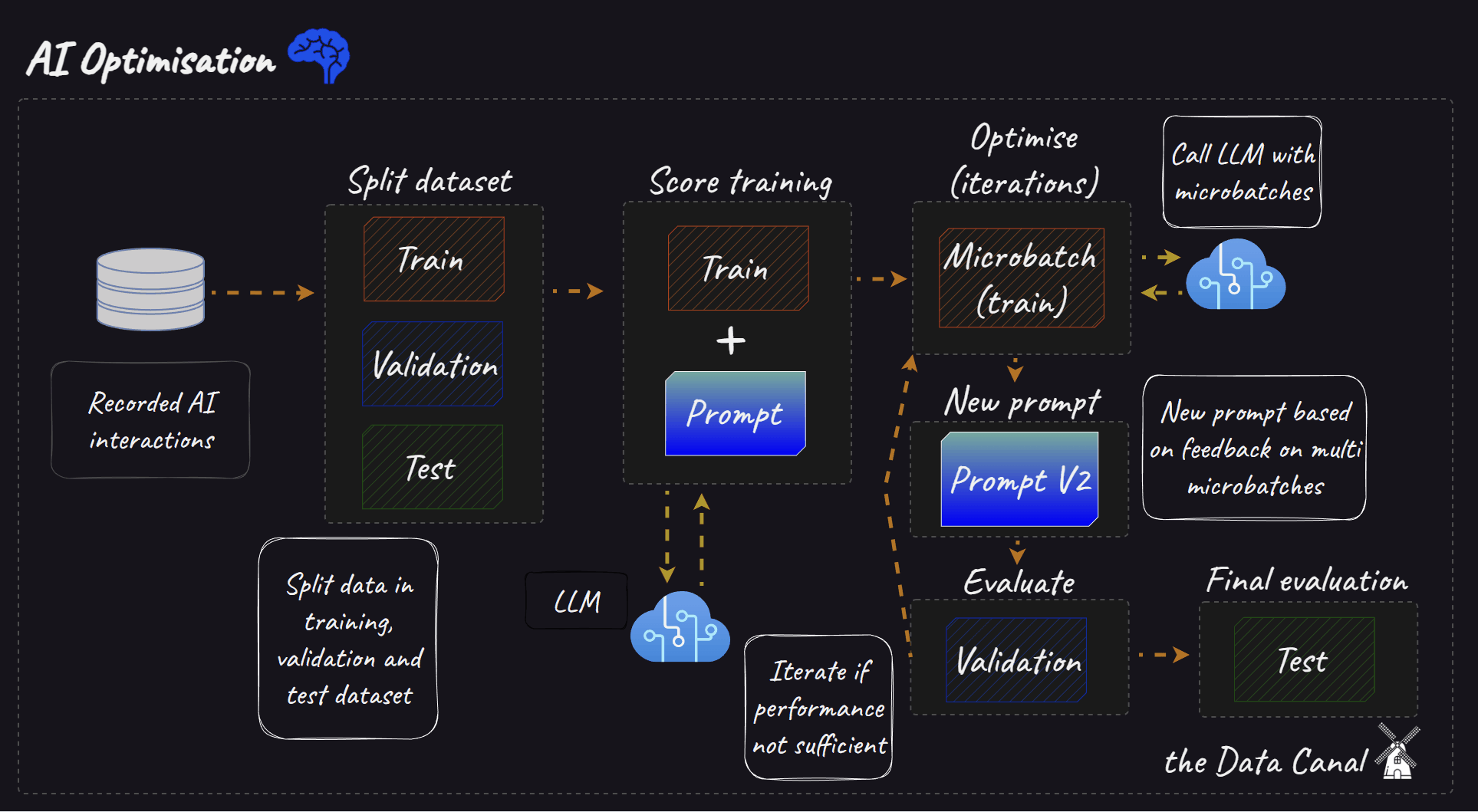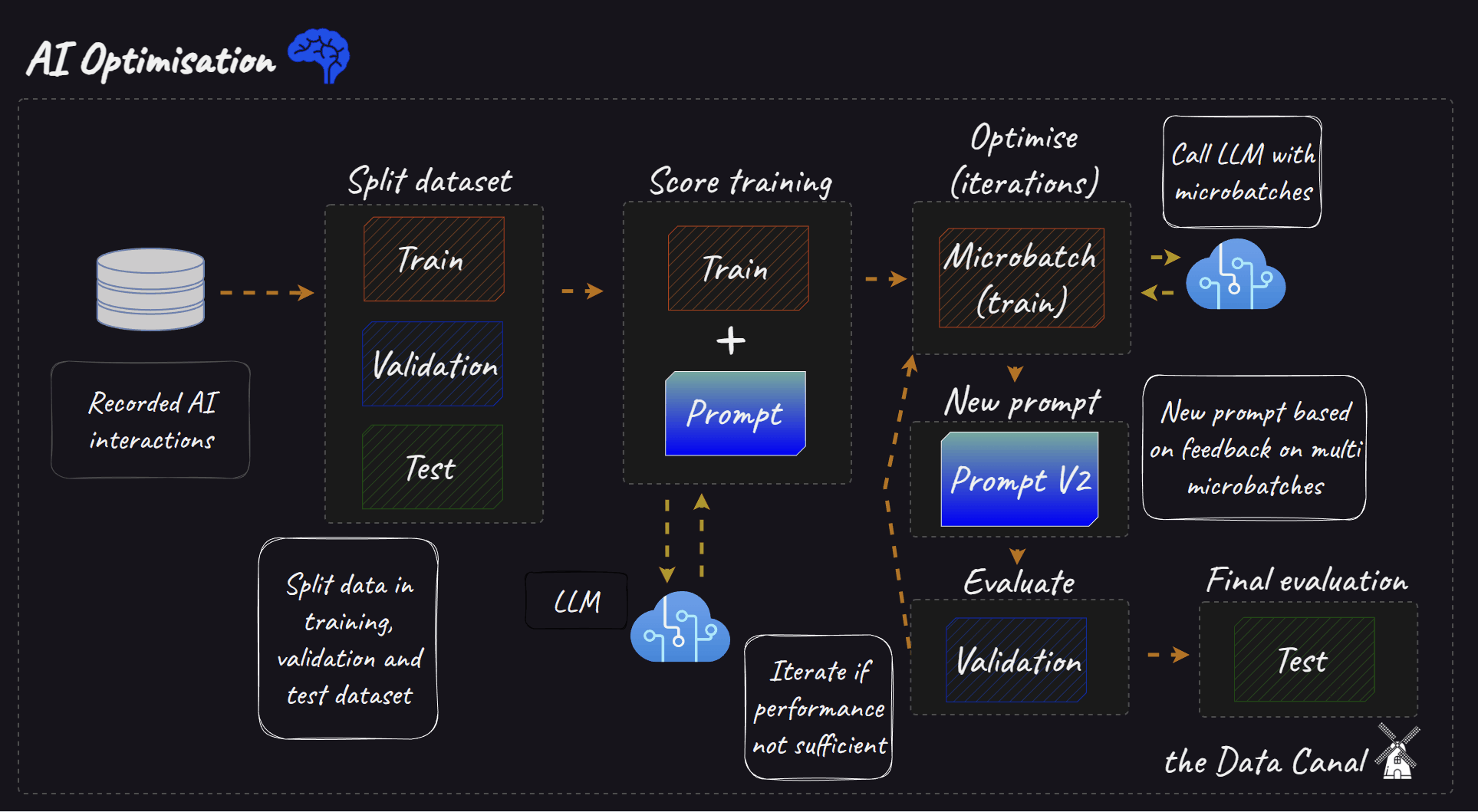
Building an AI system usually starts with a simple prompt and a single LLM call. This simple prompt gives a baseline on which “performance” can be compared. Tweaking the prompt manually might be sufficient to improve performance initially. But at some point most AI systems become more complex by either adding more prompts, LLM calls or even a Retrieval Augmented Generation (RAG) element. At this point manually tuning prompts and configuring RAG components is often a time-consuming, fragile process. A slight change in your prompt or lookup might have significant unintended side-effects.
Enter the realm of automated prompt optimisation. No longer there's a need to manually intervene in your AI system, but rather changes to it are driven by an optimisation process. The crux? The only thing you need to a metric which you can evaluate AI performance against.
This post explores how frameworks like TextGrad and AdalFlow use textual feedback to optimise prompts and RAG pipelines for specific performance metrics, potentially revolutionising how we build and refine advanced LLM applications.
We'll be covering:
The challenge of optimising complex LLM systems.
Introducing TextGrad and AdalFlow: Frameworks for automated optimisation.
The core mechanism: How textual feedback drives improvement.
Optimising prompts for better performance.
Optimising RAG pipelines: Tuning retrieval and reranking.
Let's dive into how these frameworks bring a more precise approach to LLM optimisation.
The challenge: Manual tuning in a complex world
Anyone who has worked extensively with LLMs knows the sensitivity of prompts. Studies into prompt sensitivity show that slight changes in wording can lead to significant variations in output quality, sometimes affecting accuracy by as much as 76%, according to a recent study (source). Engineers building AI products often spend the majority of their time (reportedly up to 90%) painstakingly engineering prompts rather than building the core application logic. This process can be labour intensive and often feels more like an art than a science.
When we move to RAG systems, the complexity multiplies. We now have interconnected components:
Retriever: Responsible for finding relevant information from a knowledge base.
Reranker (optional): Refines the order of retrieved documents based on relevance.
Generator: Synthesises an answer based on the query and the retrieved (and possibly reranked) context.
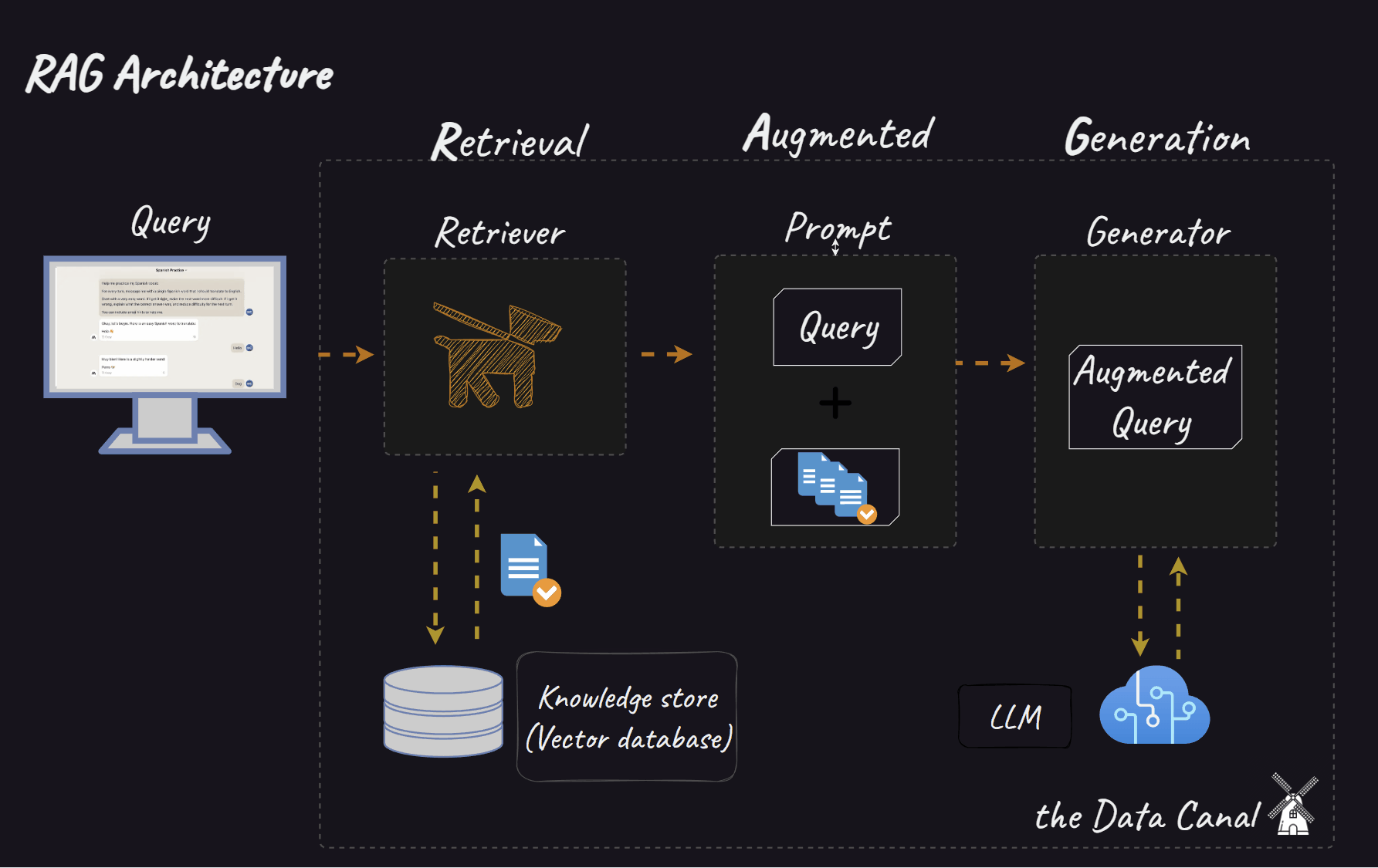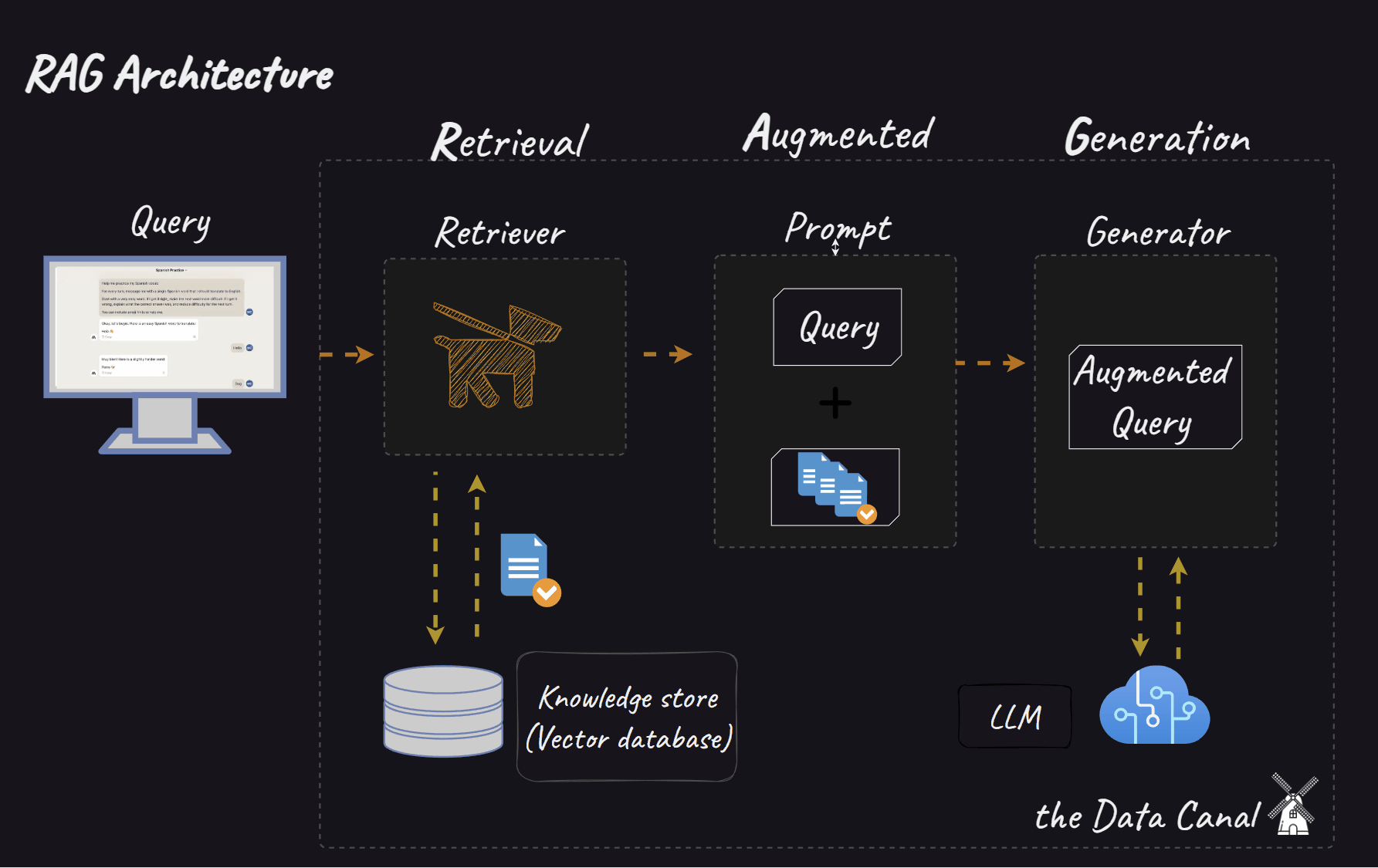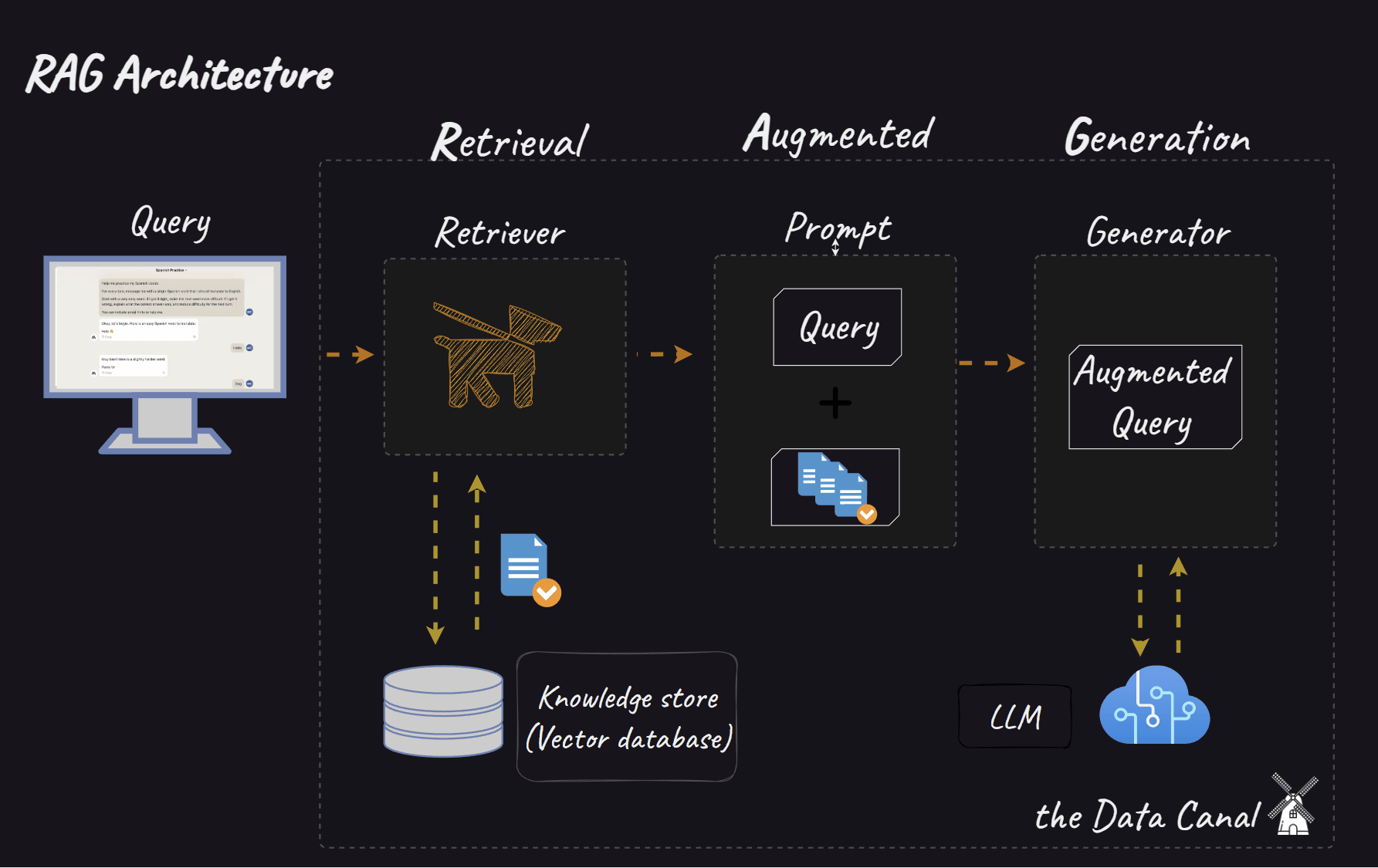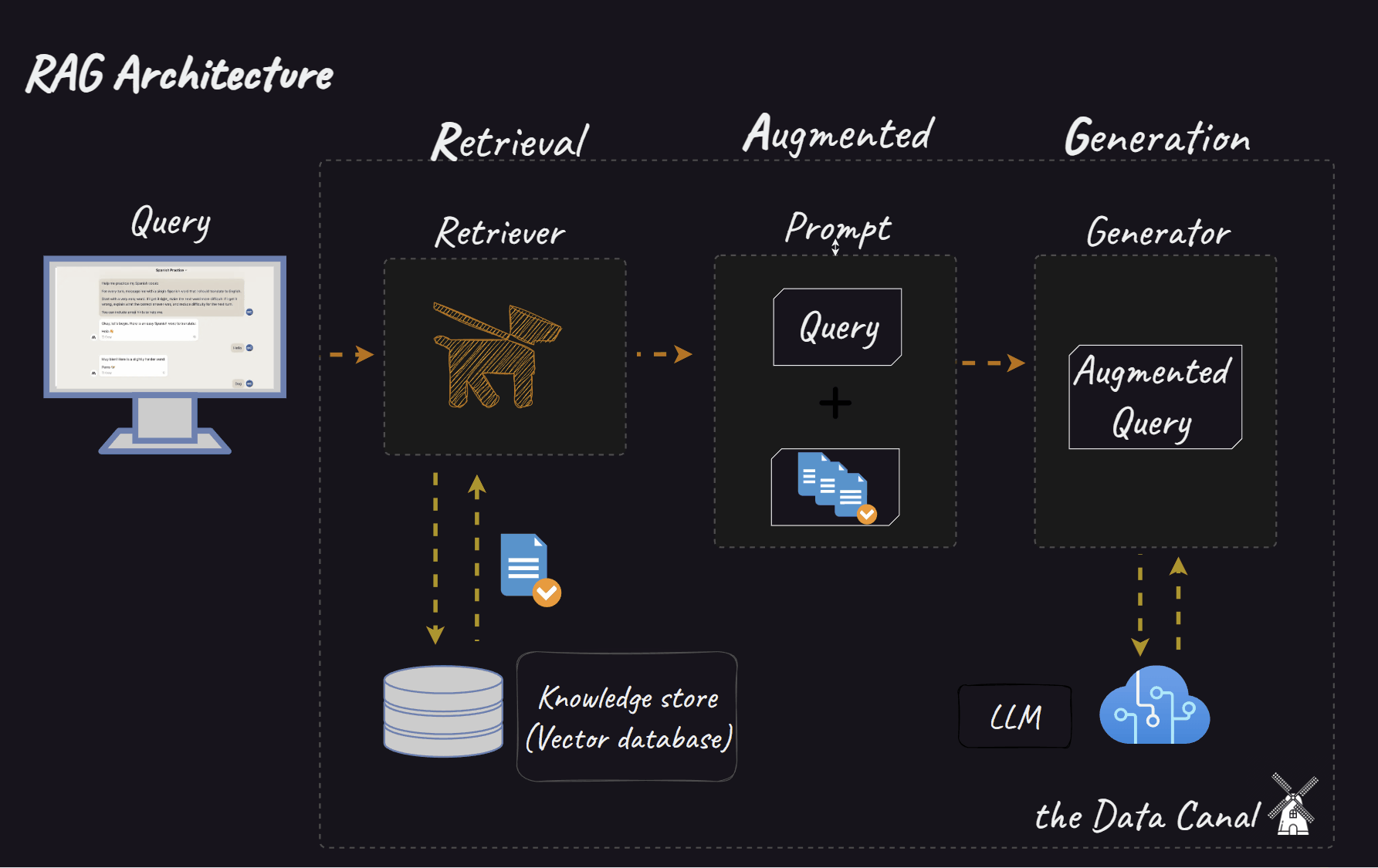
Introducing TextGrad and AdalFlow: Automated optimisation via text
Both TextGrad and AdalFlow position themselves as optimisation frameworks, analogous to PyTorch but for AI systems using textual feedback. Both introduce the idea of backpropagating textual critiques provided by an LLM to improve various components ("variables") within a computational graph. These variables can range from prompts and code snippets to more exotic structures like molecular designs.
TextGrad aims to be flexible and easy to use, requiring users primarily to define the objective function rather than manually tuning framework components. TextGrad is a more foundational methodology on how to use textual feedback to optimise AI systems.
AdalFlow builds upon a similar philosophy as PyTorch's design philosophy for building and auto-optimising LLM task pipelines with efficiency and performance in mind. It emphasises simplicity through minimal core abstractions (like its Component and DataClass structures), prioritises the quality of its building blocks over numerous integrations, and maintains a strong focus on the optimisation process itself, offering tools to ease the common frustrations in tuning. AdalFlow explicitly targets pain points like prompt optimisation and RAG pipeline tuning, aiming to automate the manual effort involved. It leverages concepts like textual feedback, potentially integrating or aligning closely with the ideas pioneered by TextGrad, to automatically refine prompts and pipeline configurations.
The core mechanism: Textual feedback as a gradient
The key innovation in both frameworks is the use of LLMs as evaluators or "critics" to provide actionable feedback in natural language. Think of it like this:
Define an objective: You specify what success looks like. This is tied to a metric. Examples include:
Binary classification metrics: Is the LLM's classification output (e.g., 'spam'/'not spam') correct compared to a ground truth label?
Answer relevance (LLM based output metric): How well does the generated answer address the user's query? This might be measured on a scale (e.g., 1 to 5) or judged qualitatively. Other metrics could include comprehensiveness, conciseness, or adherence to a specific format.
Execute the system: Run your prompt through the LLM, or execute your entire RAG pipeline.
Evaluate with a critic LLM: Use another LLM (the critic) to assess the output against the defined objective. Crucially, the critic doesn't just output a score; it provides textual feedback.
For binary classification: "The classification was incorrect. The prompt seems to overemphasise term X, leading to a misclassification. Consider focusing more on context Y."
For answer relevance: "The generated answer is too generic and doesn't use the specific details from the retrieved documents. It needs to be more grounded in the provided context."
Apply the "Textual Gradient": TextGrad and AdalFlow interpret this textual feedback and use it to suggest modifications to the optimisable components (the "variables"). This is the "automatic differentiation via text." The framework translates "Consider focusing more on context Y" into an actual change in the prompt text, or "Answer is too generic" into adjustments potentially affecting the generator's instructions.
Iterate: Repeat the process. The modified component is used, a new output is generated and evaluated, and further feedback refines the component iteratively, hopefully improving the target metric over time.
Optimising prompts with textual feedback
Prompt optimisation is a prime use case highlighted by AdalFlow. Here, the prompt itself is the variable being optimised.
The process looks like this:
Split your dataset into a train, validation and test set and pick an evaluation metric to assess performance.
Start with an initial prompt (zero-shot or few-shot).
Use the prompt with your target LLM to generate outputs for a set of evaluation examples based on your train data.
In micro-batches (e.g. two correct and two incorrect examples), have the critic LLM evaluate these outputs against your metric (e.g., accuracy, relevance).
The critic provides textual feedback specifically about the prompt's effectiveness (e.g., "The instructions are unclear," "The examples provided are misleading," "Needs to explicitly ask for step-by-step reasoning").
The framework (TextGrad/AdalFlow) uses this feedback to automatically rewrite or adjust the prompt and if applicable changes the one/few-shot examples. If a RAG element is part of the pipeline it can also optimise this, more on this in the next section.
Evaluate the performance on the validation set.
This cycle repeats, iteratively refining the prompt. Stop if a certain metric threshold or a number of iterations is hit.
Evaluate overall performance on the test set.
AdalFlow reports significant success with this, citing an example where auto-optimisation boosted classification accuracy from 83% to 95%, outperforming even state-of-the-art manual methods, demonstrating the power of automated textual feedback loops.
Optimising RAG pipelines: Beyond the prompt
Optimising RAG systems involves more than just the final generation prompt. Textual feedback can be applied to multiple stages:
Retriever optimisation: The goal is to fetch the most relevant documents. A critic LLM can evaluate the relevance of the retrieved passages before they even reach the generator.
Feedback example: "Retrieved document 3 is highly relevant but documents 1 and 2 are off-topic for this query."
Optimisation action: This feedback could potentially guide adjustments to the retrieval query, the embedding model used, the number of documents to retrieve (top-k), or parameters within the retrieval algorithm itself.
Reranker optimisation: Rerankers aim to place the most relevant documents at the very top of the list presented to the generator. Textual feedback can assess the quality of this re-ordering.
Feedback example: "The reranker placed the most critical piece of information fourth. It should have been ranked first."
Optimisation action: This feedback could be used to change the reranking model or adjust it to improve its ability to prioritise the necessary context.
Generator optimisation (within RAG): Even with perfect retrieval and reranking, the generator needs to synthesise the information effectively. The prompt used by the generator is a key variable here.
Feedback example: "The answer correctly identifies the key facts from the context but fails to synthesise them into a coherent summary." or "The answer hallucinates information not present in the provided documents."
Optimisation action: This feedback drives iterative refinement of the generator's prompt, similar to the standalone prompt optimisation described earlier, but specifically tailored to the context-aware generation task.
By applying targeted textual feedback at each stage, frameworks like TextGrad and AdalFlow can holistically optimise the entire RAG pipeline, addressing bottlenecks wherever they occur, whether in retrieval, reranking, or generation. AdalFlow demonstrates its capabilities by optimising AI systems with RAG on datasets like HotpotQA (see here). This underscores the applicability of these techniques to complex, multi-stage reasoning and retrieval tasks.
Final thoughts: Towards self-optimising AI systems
TextGrad and AdalFlow represent a significant step towards more automated and accurate methods for developing and refining complex AI systems. By using LLMs as critics that provide actionable textual feedback, they offer a way to bypass the tedious and sometimes unreliable process of manual tuning.
While still relatively new, these frameworks promise to:
Reduce development time and effort.
Potentially achieve better performance by systematically exploring the optimisation space.
Make advanced techniques like RAG more accessible and manageable.
The ability to optimise for specific, measurable metrics using intuitive natural language feedback could fundamentally change how we build and deploy the next generation of AI applications.
What are your thoughts on using textual feedback for optimisation? How might these techniques change your LLM development workflow?
Thanks for reading The Data Canal! Subscribe to this free blog for more posts on cutting-edge developments in the world of Data & AI. Interested in becoming a writer for The Data Canal? Feel free to reach out