
Airflow 3.0: DAG versioning, multi-language support and native AI/ML workflows
The biggest release for Airflow in years is coupled with a few long outstanding quality of life changes. What are those, and how will it improve your day-to-day as an Airflow user?

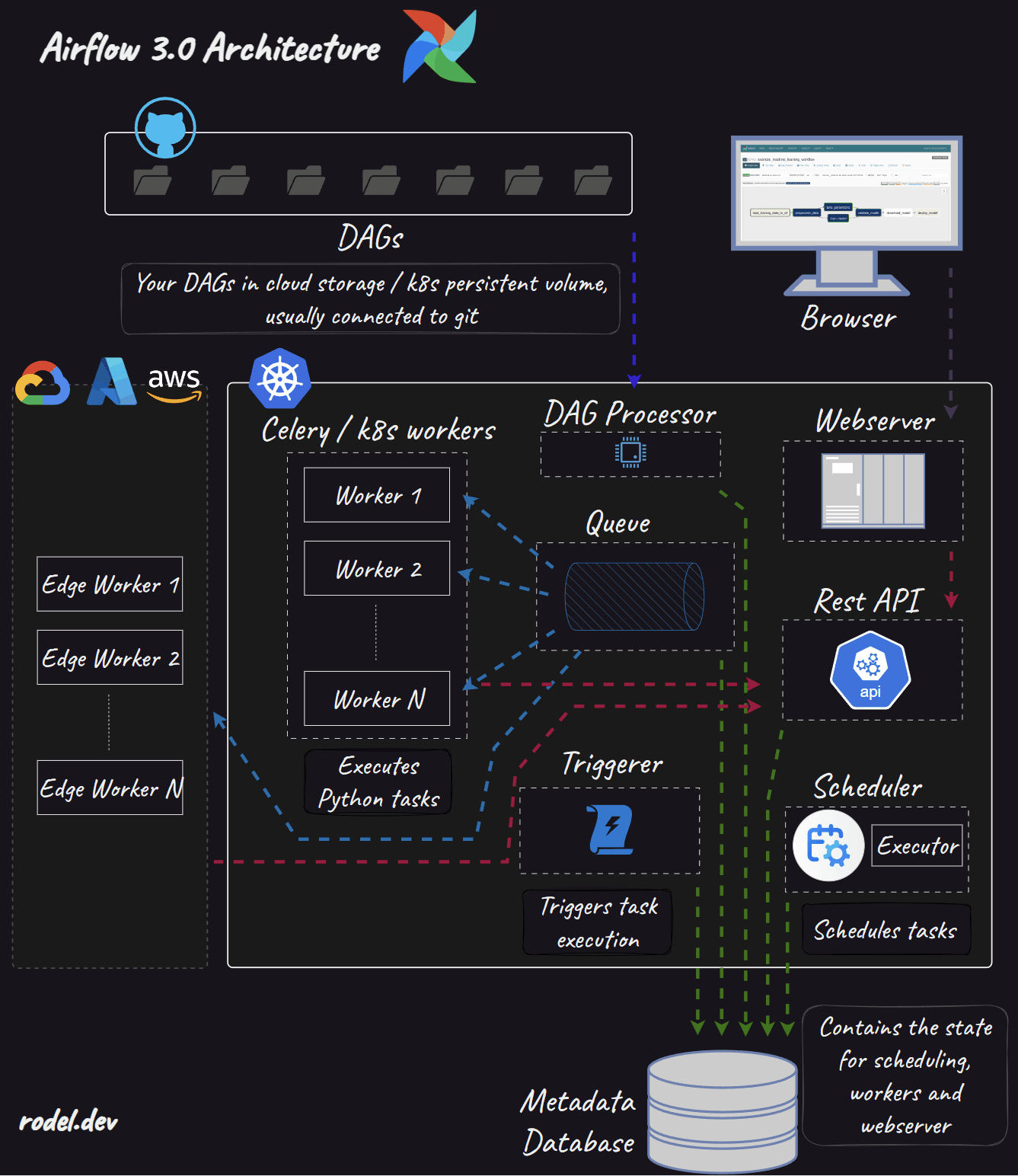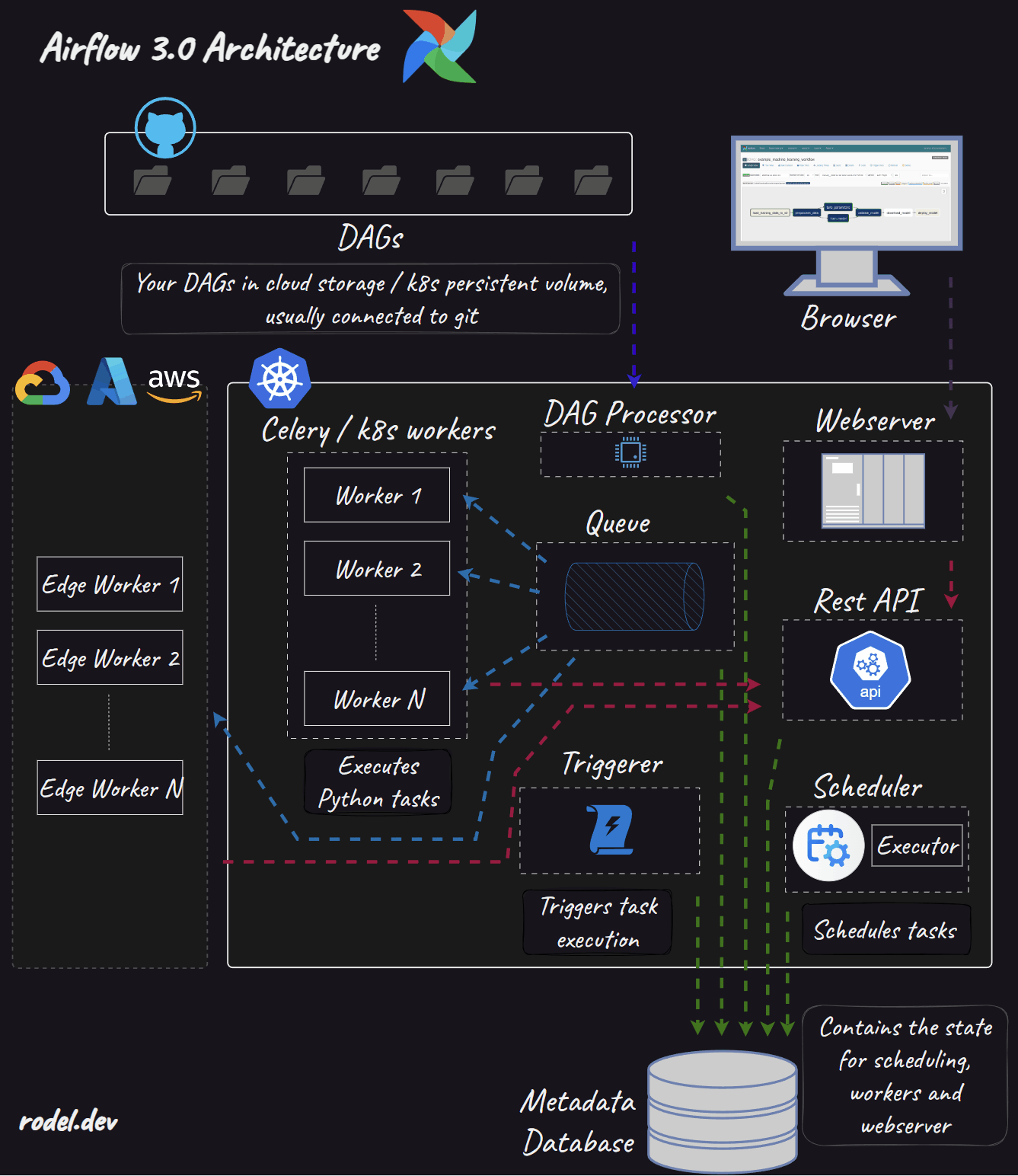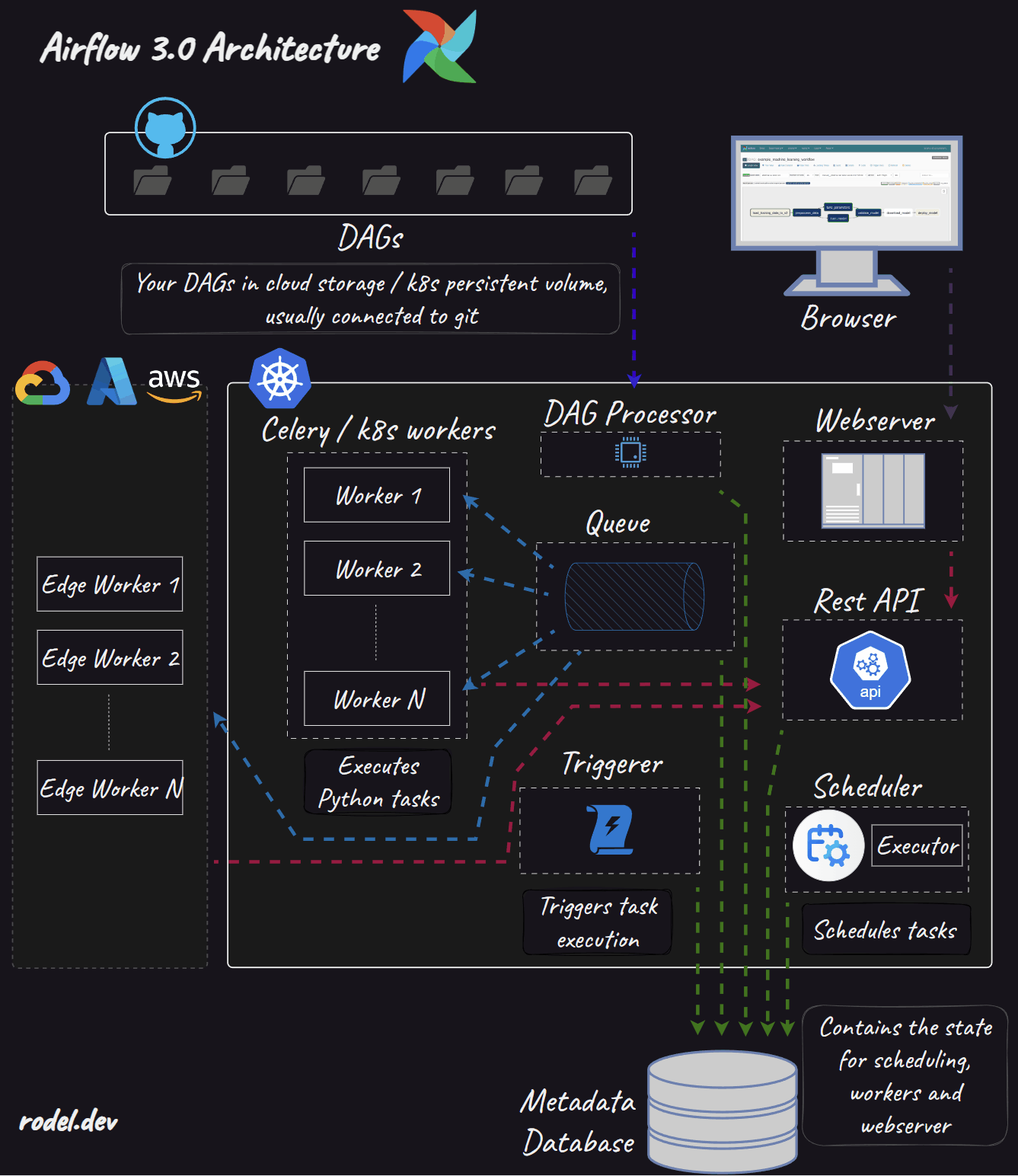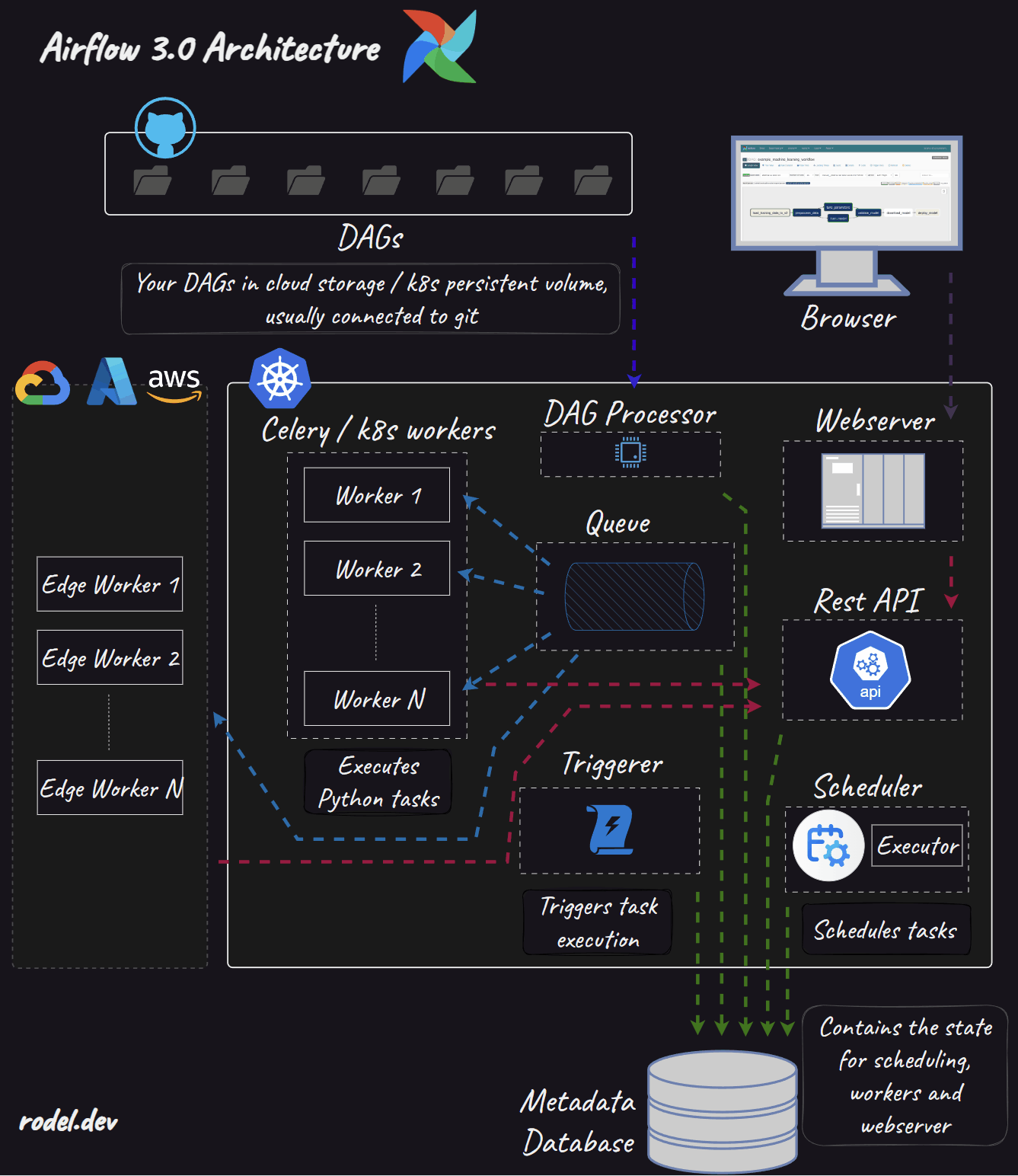
Apache Airflow 3.0® is on the horizon, and it's promising to be a transformative release. Due to popular demand this post is dedicated to describing Airflow 3.0 features that will enhance the quality-of-life for (daily) Airflow users.
In a previous post (Airflow 3.0: Architectural changes), a deep-dive was done on a few of the feature updates, such as external workers and the modernised UI, and their impact on the Airflow architecture. While the buzz around those features is well-deserved, some equally crucial, yet less discussed improvements are coming to fundamentally change how we build, manage, and debug our Airflow DAGs. This post aims to prepare you by diving into a few of these pivotal changes, exploring how they'll impact your daily Airflow experience.
We'll be covering:
DAG version history: DAGs and their tasks will be versioned to ensure reproducibility, rollbacks and to keep track of a DAG's overall and task lineage.
Scheduler-run backfills: Backfills are no longer a second-class citizen that could only be ran through the CLI. Scheduler-run backfills are here to provide a more native backfill experience without the hassle of separate backfill DAGs or CLI based workflows.
Beyond Python: Airflow has always been a Python-first tool, where both its DAGs and code execution could only be ran in Python. As part of Airflow 3.0 this will all change, no longer you need to use workarounds to run code in other languages.
Airflow as an AI/ML orchestrator: From its inception Airflow has focused on date dependent workflow execution. This makes it more difficult to build DAGs around other concepts such as ML training or AI inference workflows. In this release Airflow will let go of the required date based execution, which will make a difference for AI/ML workflows.
Let's start with a feature that's been on the wish list of many Airflow users for a long time: DAG versioning.
1. DAG version history: Unlocking the secrets of the past
A persistent headache for Airflow users is understanding how a DAG behaved in the past. As business needs evolve, DAGs inevitably change, and tracking those changes has been a challenge. Currently, Airflow only displays the latest state of a DAG, leaving you in the dark about its structure, code, and even task instance logs for previous states. Imagine trying to debug an old DAG run only to find the task has vanished from the web UI.
Airflow 3.0 addresses this by delivering a comprehensive DAG version history. Every task instance run will now display the exact DAG structure, the code used to generate it, and access to historical logs, providing a complete and accurate snapshot of past executions.
What will change in the web UI
As a part of the new improved UI, DAG version information will be shown. For example as part of the DAG view, a DAG version will be shown. In addition, will toggles be added to switch between different versions of the DAG in the DAG view. Tasks that have been removed, will now be shown in the UI and will be retained in the grid view, but without status indicators for subsequent runs, making it easy to identify what changed.

This feature will allow seeing the precise arrangement of tasks and their dependencies as they existed during a specific run. This is especially critical when DAGs are modified mid-execution, a scenario that currently leaves the UI showing an inaccurate or incomplete picture. You'll finally be able to accurately visualise the flow of tasks for each individual DAG run. Think of it like having a historical map for every journey your data takes.
Reproducability: Code and log level tracability
Equally critical to ensure reproducability is access to the exact DAG file code that generated a historical workflow, ensuring you know the logic that was executed. This isn't just about seeing the Python code; it's about understanding the precise configuration of operators, parameters, and dependencies that defined the DAG's behaviour. This granular level of detail is crucial for debugging, auditing, and replicating past runs. The Airflow UI will now show which version of the DAG was used, meaning that you can access the exact code that was used for your DAG Run and Task Instances runs.
Another long asked for feature is that task instance logs will remain accessible even for tasks that no longer exist in the latest DAG version. Previously, if a task was removed, its logs were effectively orphaned, making it difficult to diagnose issues in past runs. With DAG versioning, those logs are now linked to the specific version of the DAG, ensuring that no information is lost. Now you will have an easier time debugging your DAGs with all the available log information that the specific DAG version used.
How does it work?
A question that naturally comes up is “How does Airflow do this?” As part of Airflow 3.0, DAG versions are determined by hashing the serialised DAG JSON, capturing changes to the DAG structure. This is a robust and efficient method, ensuring that even subtle modifications are detected. The system will also track the DAG version at the TaskInstance attempt level, providing the granularity needed to handle complex scenarios where DAGs change mid-run. In addition, future versions may explore support for user-provided version strings for easier identification.
With the introduction of DAG versioning, Airflow provides a more transparent and auditable platform, empowering you to confidently manage evolving workflows and troubleshoot historical runs with ease. No more guessing, just clear historical information. The result will be a more efficient debugging process and a more accurate representation of how your DAGs ran in the past. If you want in-depth insights into the changes, read about it here:
2. Backfilling as a first-class citizen
Backfilling, the process of running a DAG for past dates, has always been a somewhat clunky experience in Airflow. Currently, the only way to initiate a backfill is through the command-line interface (CLI), which presents several limitations. In Airflow 3.0, backfilling gets a major upgrade, becoming a first-class citizen with native support within the scheduler and web UI.
The problem with CLI-only backfills
The existing CLI-based backfill process suffers from several drawbacks:
CLI dependency: Users need direct access to the Airflow CLI, which isn't always feasible or desirable, especially in environments with strict access controls.
Synchronous execution: The CLI backfill command acts as a second scheduler, running tasks directly. If the CLI process dies, the backfill job is interrupted. This is hardly ideal for long-running backfills.
Maintenance overhead: Maintaining a separate backfill scheduler alongside the main scheduler creates extra work and increases the risk of behavioural divergence as Airflow evolves.
Introducing scheduler-run backfills
Airflow 3.0 addresses these issues by fundamentally changing how backfills are handled. Here's what you can expect:
API-triggered backfills: Backfill jobs can now be triggered asynchronously via the Airflow API, giving you more flexibility and control.
Scheduler management: The Airflow scheduler will manage the backfill job, creating DAG runs and scheduling tasks according to defined parameters. This ensures that backfills are executed reliably and efficiently, even in the face of interruptions.
Web UI integration: You'll be able to view backfill jobs in the webserver, observe progress and status, and even pause or cancel them as needed.
Imagine the power of initiating a backfill job directly from the UI with just a few clicks, and then monitoring its progress in real-time. This eliminates the need for complex CLI commands and provides a much more intuitive and user-friendly experience.
What's changing?
To achieve this streamlined backfill experience, several changes are being made under the hood:
Removal of the backfill scheduler: The CLI backfill command will no longer run any tasks directly. Instead, it will create a backfill job, and the scheduler will take over from there.
BackfillRun model: A new ORM model, BackfillRun, will be introduced to track backfill jobs. This model will store information such as the DAG ID, start and end dates, and other configuration parameters.
Backfill priority: Backfills will have their own “max_active_runs” setting that will apply to just those dag runs in the particular backfill run. The DAG “max_active_runs” setting will not be considered. Backfill dag runs will not be counted against non-backfill runs, and vice versa.
What's going away?
To simplify the backfill process and align it with the core Airflow scheduler, several parameters will be removed from the backfill command:
continue_on_failures: This feature, which cancelled a backfill job after any failure, will be removed. The new system allows for pausing and cancelling jobs manually.
task_regex: Running a backfill on a subset of tasks will no longer be supported. This simplifies the backfill logic and ensures that all dependencies are properly handled.
ignore_dependencies: This confusing parameter will be removed.
local: Local execution of backfills will no longer be supported. All tasks will be handled by the scheduler with the configured executor.
With these changes, Airflow 3.0 transforms backfilling from a cumbersome CLI task into a well-integrated and easily manageable part of the Airflow ecosystem. This will save you time and effort, and allow you to focus on what matters most: getting your data pipelines up and running. In-depth information can be found in AIP-65: Improve DAG history in UI.
3. Language agnostic task execution: Breaking free from Python
For years, Airflow has been primarily a Python-centric tool both for defining DAGs and executing tasks. While Python's flexibility and extensive ecosystem has been a perk, it has also imposed limitations, particularly for organisations with diverse technology stacks and specialised skillsets. Airflow 3.0 is set to change the language limitation for tasks with the introduction of language-agnostic task execution, allowing you to seamlessly integrate tasks written in other languages, such as Golang or Typescript, into your workflows.
The challenges of a Python-centric task execution
The current reliance on Python for task execution presents several challenges:
Dependency conflicts: Managing dependencies across different data teams, each using various versions of providers, libraries, or Python packages, can be a logistical nightmare. This often leads to dependency conflicts and operational headaches.
Security concerns: Running customer-defined code (task code within DAGs) from multiple customers within the same operating environment and service accounts raises significant security concerns.
Operational complexity: Supporting diverse data teams with a common Airflow environment is challenging, as different teams naturally operate at different velocities and have varying requirements.
The new task SDK: Language flexibility and more
Airflow 3.0 aims to overcome these challenges by enabling a clean, language-agnostic interface for task execution. This means you can write tasks in languages beyond Python, while still leveraging Airflow's powerful scheduling and orchestration capabilities. For now, only task execution is being opened up to different languages; DAGs will still need to be defined in Python.
Airflow 3.0 introduces a new Task SDK and API to facilitate language-agnostic task execution.
Task SDK: The Task SDK provides a slimmed-down interface for tasks to interact with Airflow. This includes access to connections, variables, XCom values, logging, and metrics reporting. It will initially be available for Python, with bindings for other languages like Golang and Typescript following soon after.
API: A new HTTP-based API will serve as the primary communication channel between tasks and the Airflow environment. This API will be strongly versioned using CalVer to ensure compatibility and support multiple versions in parallel.
With this new architecture, tasks will no longer have direct access to the Airflow database. Instead, they will communicate with the API server using a secure JWT token. The API server will then handle all database interactions and enforce access control policies.
Overall, the new approach gives several key benefits:
Reduced dependency conflicts: By isolating task execution from the core Airflow environment, you can minimise dependency conflicts and create more stable and reliable workflows.
Enhanced security: The new Task SDK (Software Development Kit) and API provide a more secure environment for running user code, with optional pre-declaration of variables and connections to improve security.
Improved scalability: The move away from direct database access for tasks reduces the number of concurrent database connections, improving Airflow's scalability.
Greater flexibility: You can leverage the strengths of different languages for specific tasks. For example, you might use Golang for high-performance data processing or Typescript for front-end related tasks.
Opening new horizons: Potential use cases
The ability to execute tasks in different languages opens up a wide range of possibilities:
Golang for high-performant data processing: Leverage Golang's performance and concurrency capabilities for data-intensive tasks like ETL and data transformation. In addition, if your back-end is written in Golang it offers the ability to align your data engineering pipelines further with your back-end.
Typescript for front-end related tasks: Integrate tasks that interact with front-end systems, such as triggering deployments or updating dashboards, using Typescript. This will allow wider use cases for Airflow as tasks can be written directly by domain experts (e.g. front-end, back-end, security engineers, etc)
Specialised language support: Use languages that are best suited for specific tasks, such as R for statistical analysis or Java for enterprise applications.
Airflow 3.0's language-agnostic task execution is a game-changer that empowers you to build more flexible, scalable, and secure data pipelines. By breaking free from the limitations of Python, you can leverage the best tools for the job and create workflows that are tailored to your specific use case and your team's expertise. For more details refer to AIP-72 Task Execution Interface aka Task SDK.
4. Dropping the execution date requirement
From its inception, Airflow's architecture has been tied to the concept of an “execution_date”. This date, representing the logical point in time for which a DAG run is processing data, served as a primary identifier for DAG runs and task instances. While this approach worked well for traditional, time-dependent data pipelines, it introduced limitations when applying Airflow to more general workflow orchestration, particularly in the realm of AI/ML. With Airflow 3.0, this limitation is lifted through the removal of the execution date uniqueness requirement, opening the door for seamless integration with AI/ML workflows.
The problem with unique logical dates in AI/ML
In many AI/ML scenarios, the notion of a specific "execution date" is irrelevant or even misleading. Consider these examples:
Model training: A DAG might be designed to train a machine learning model. The DAG run isn't tied to a specific point in time, but rather to the availability of new training data or the desire to improve model accuracy.
AI inference: An AI inference DAG might continuously serve predictions based on incoming requests. There's no fixed schedule or execution date associated with these runs.
Data labeling pipelines: A data labelling pipeline might involve human annotators labelling images. The "execution date" doesn't represent a real-world time but rather a stage in the labelling process.
In these cases, forcing a relation to a specific date becomes artificial and introduces unnecessary complexity. Workarounds, such as manually manipulating execution dates, become awkward and can lead to confusion. Crucially, the existing architecture makes it difficult to trigger DAGs dynamically, especially when using the TriggerDagRunOperator, as it requires a unique execution date for each triggered run.
From a unique execution date to an optional logical date
Airflow 3.0 introduces a significant change by removing the unique constraint on execution date in the database and deprecating its use in various API functions. This means that you no longer need to shoehorn your AI/ML workflows into a time-based framework.
Specifically, Airflow 3.0 will:
Remove the unique constraint on execution_date: This frees you from the need to generate unique dates for each DAG run.
Remove deprecated arguments: Arguments in Python functions and the REST API that use execution_date to look up DAG runs are removed.
Remove execution_date from the task execution context: The execution_date key is removed from the task execution context, simplifying the information available to tasks.
Introduce run_id as the primary identifier: DAG runs are now primarily identified and looked up by the run_id field.
Display logical_date: The execution_date value may still be shown as the "logical date", for informational purposes and to help users distinguish between runs, but it's no longer a technical requirement.
Impact on AI/ML workflows
The removal of the execution_date requirement unlocks a range of benefits for AI/ML workflows:
Simplified DAG design: You can design DAGs that are focused on the logic of your AI/ML process, without the need to worry about artificial dates.
Dynamic DAG triggering: Trigger DAG runs dynamically based on events, such as the arrival of new data or the completion of a model training job.
More seamless integration with ML platforms: Integrate Airflow with your existing ML platforms and tools, without the constraints of the execution_date.
Enhanced reproducibility: Combine with DAG versioning to accurately track and reproduce all aspects of your ML pipelines, from data preparation to model deployment.
Airflow 3.0's move away from the execution_date requirement marks a significant step towards making Airflow a truly versatile orchestration platform, capable of handling not only traditional data pipelines but also the complex and evolving workflows of the AI/ML world. This change empowers you to build more flexible, efficient, and scalable AI/ML solutions, opening new possibilities for leveraging Airflow in the age of AI.
Find the latest status update on Airflow 3.0's development here. What Airflow 3.0 feature are you most excited for?
The Data Canal is a free weekly newsletter that contains deep-dives into Data & AI related topics. Support my work by subscribing. Interested in becoming a writer for the Data Canal, feel free to reach out.